Insight
Imagine a world where your data is always accurate with minimal efforts thanks to AI assistance. With Sweeper AI, you can quantify and resolve the cost of damage due to bad data quality and furthermore reduce the cost of cleansing to create tangible business value, leading to a competitive advantage in your industry. Cost of damage are the costs created down the road by data errors. As an example, incorrect material master data inherits the errors to transactional data such as purchase orders, which then leads to process errors or manual fixing efforts. In the context of material planning parameters, the risk can even be more drastic. While suboptimal planning parameters can produce excess stock tying up working capital, missing or incorrect data like the material supply strategy can lead to unexpected line stoppages and production disruptions. To prevent this, the data errors must be corrected by employees, which produces a cost of cleansing.
According to Gartner, “Every year, poor data quality costs organisations an average of $12.9 million.”
An optimal material supply strategy to the line is crucial for smooth production operations. In discrete manufacturing, a missing or wrong value for a control cycle strategy parameter can lead to replenishment disruptions and line stoppages and thereby lead to delayed deliveries or even lost sales. Maintaining a parameter like the control cycle strategy often requires a high manual effort and expert knowledge due to dependencies with other fields. Sweeper AI provides a versatile toolkit to get the work done.
As not every cleansing approach requires the same technology, the Sweeper AI serves 3 maturity levels: Deterministic Rules, External Data Checks and AI. This toolset reflects the entire spectrum of complexity that occurs in data management, from missing data to difficult parameter dependencies. Not all cases require a sophisticated AI model. It is the combination of traditional rule-based methods and AI-driven techniques that provide the most value and transparency to the user.
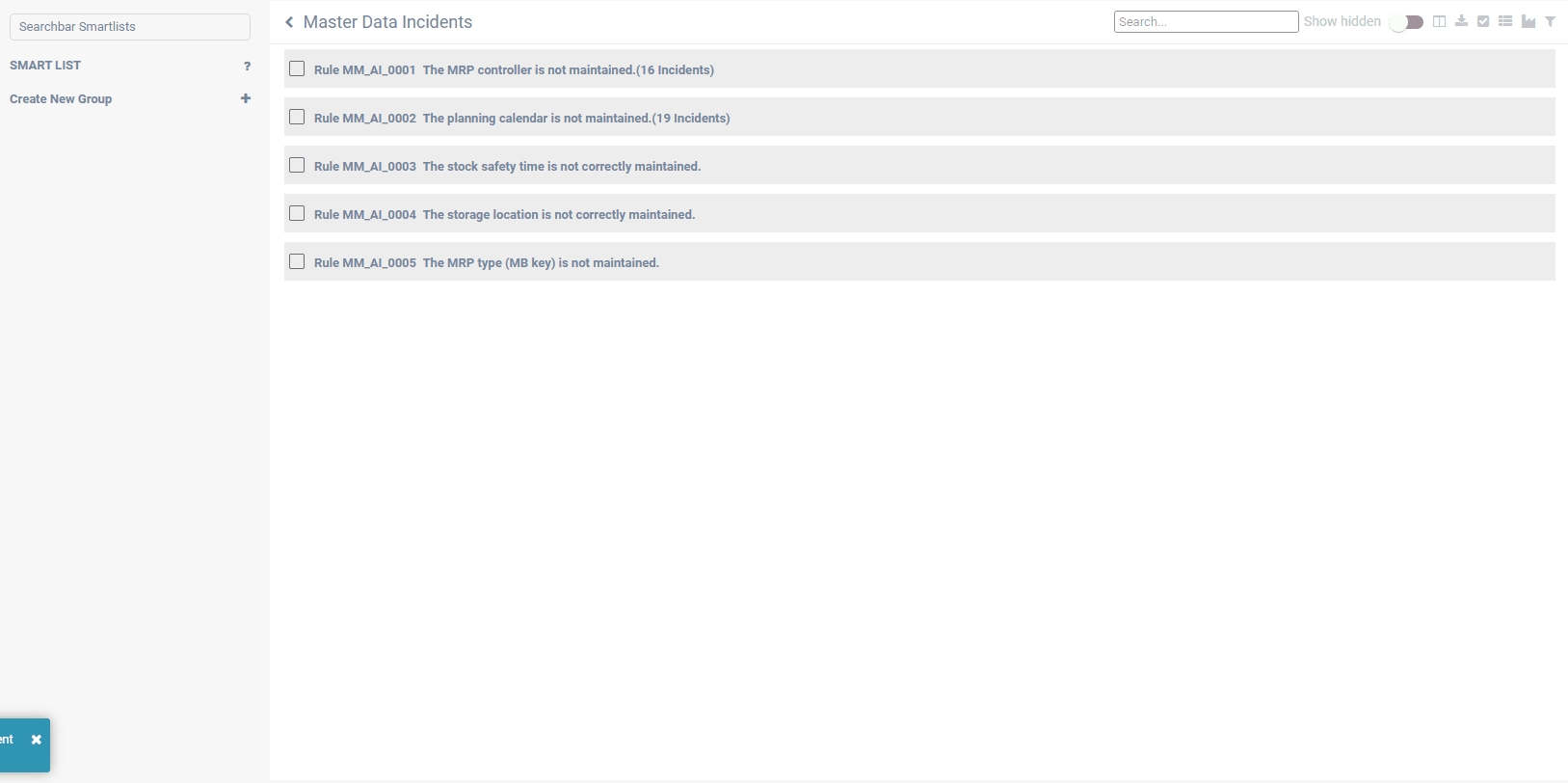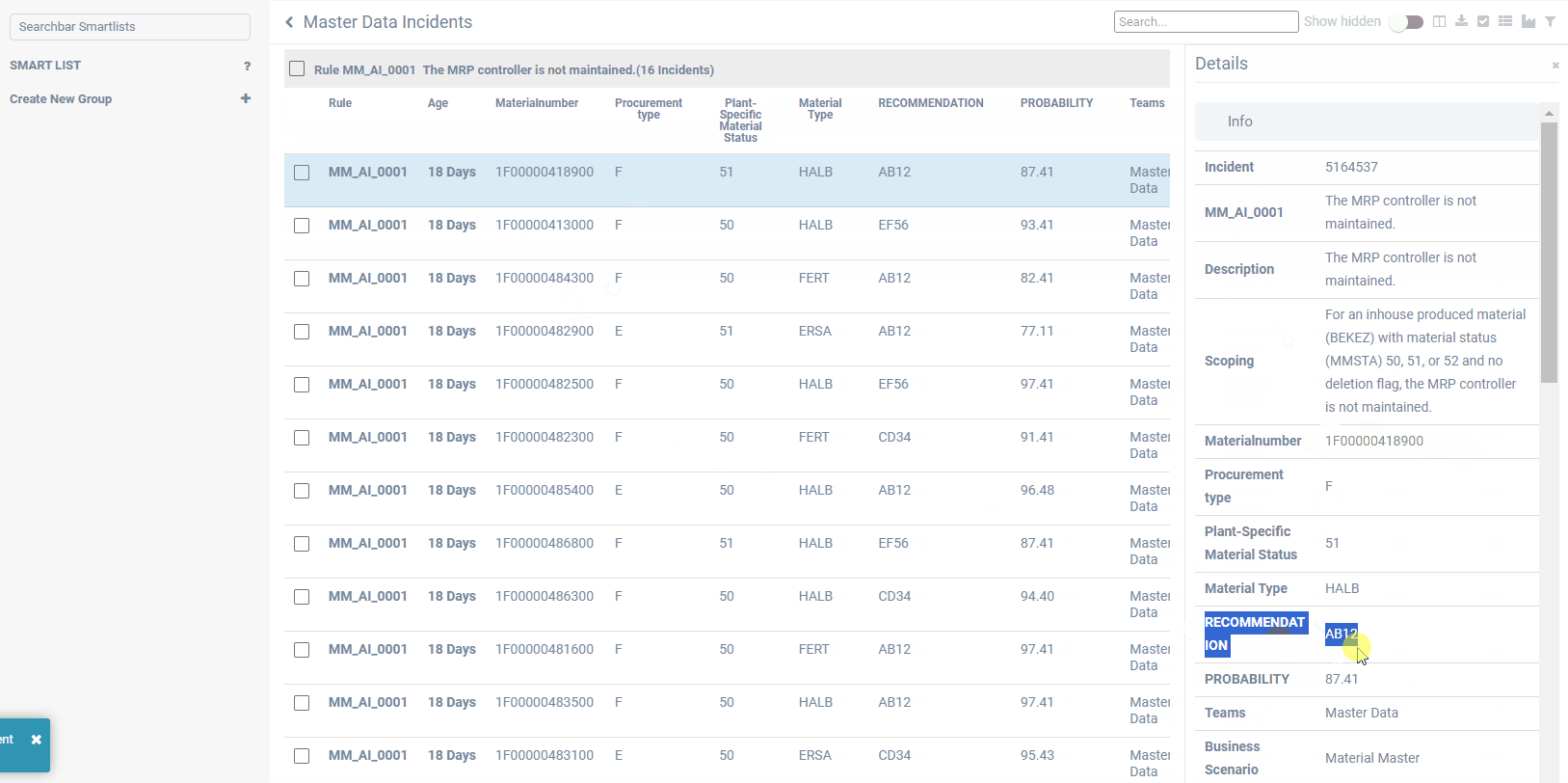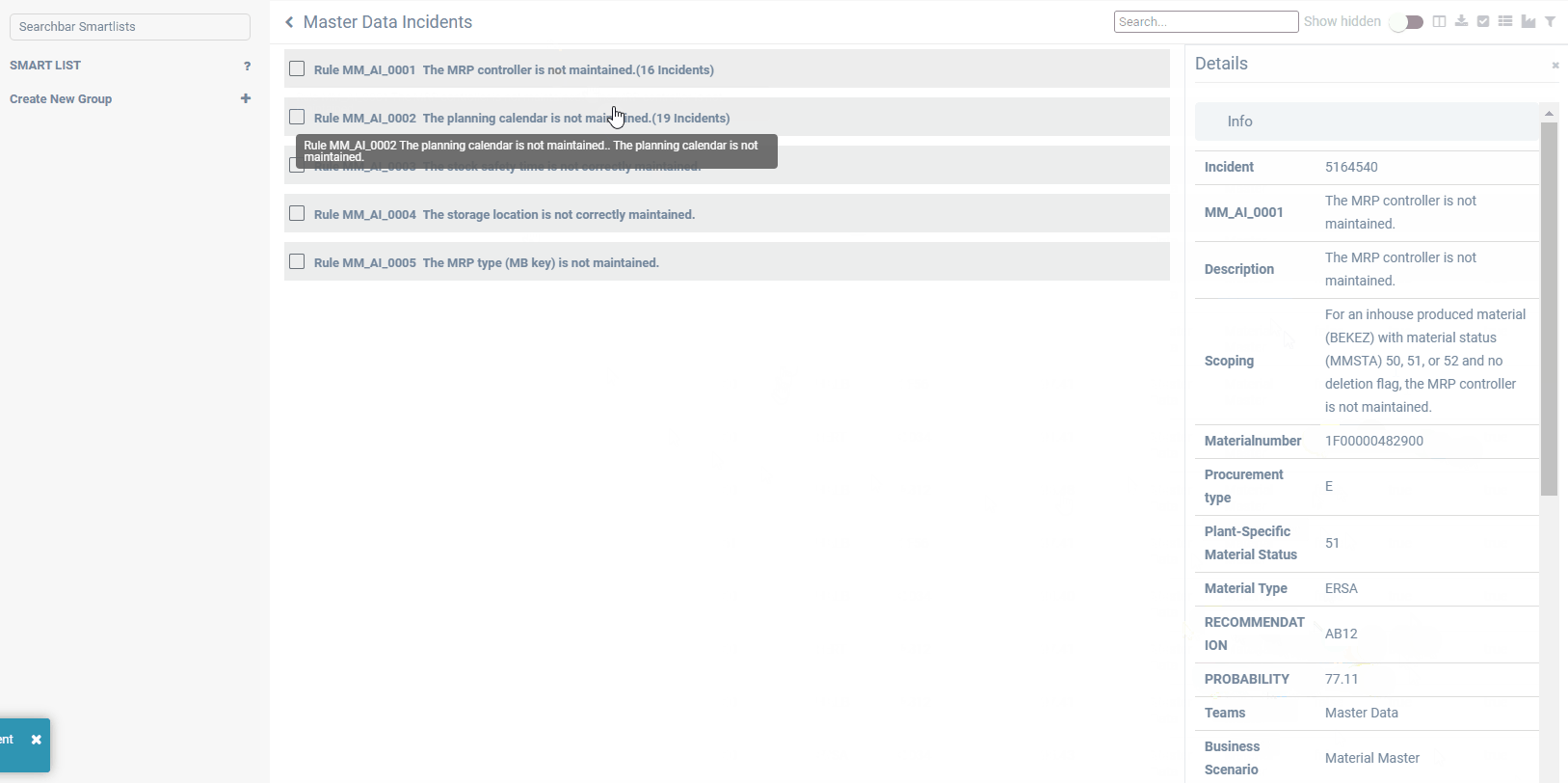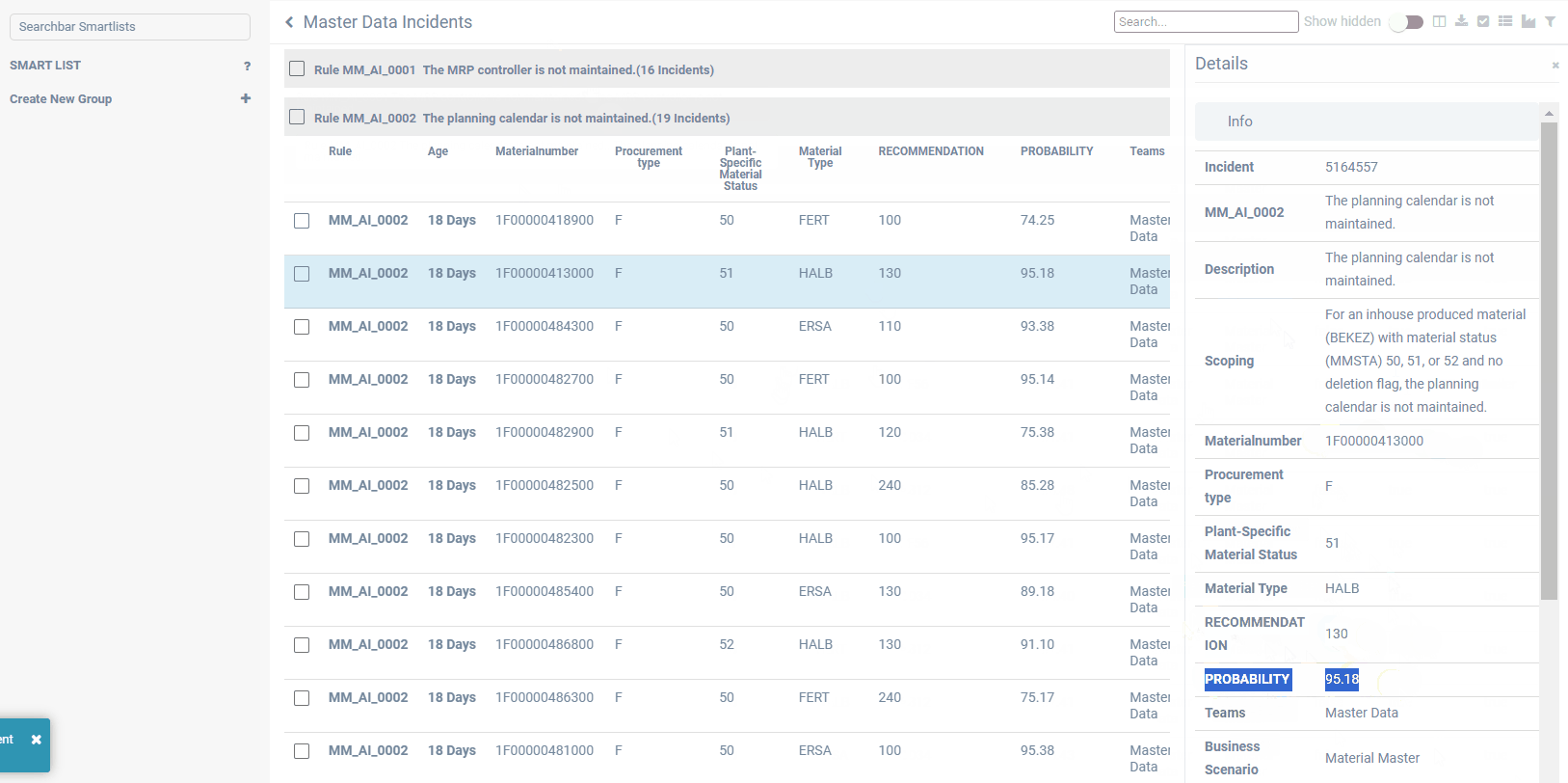
All cleansing recommendations of above-mentioned approaches are presented directly to the responsible data owner, who then can accept, change or decline. All recommendations can be validated and confirmed in an easy-to-use frontend, including a workbench with incidents to be solved for each control cycle and a progress dashboard. Continuous improvement of the recommendations is achieved by learning from the user reactions. In this way, predictions become better over time.